While the first part of this series focused on the configuration and log files of RabbitMQ, here, we will explore the data directory in great detail.
To begin, let's answer a very obvious question…
What is the data directory?
TL - DR: Exercise caution when deleting files in this directory as it can disrupt the server's state, leading to message loss, and loss of exchange, queue, or binding definitions. These files play a vital role in preserving the server's state by persisting published messages and the node's meta-data – For historical reasons, the data directory is called "mnesia". We will see later what Mnesia is, but for now let's clarify that most of the files don't belong to the Mnesia database.
The RabbitMQ data directory can rightly be described as the soul of every RabbitMQ server. More generally, it preserves the server's state by persisting messages published to queues and other meta-data like definition of queues, exchanges, and binding, amongst others.
But how – you might ask?
We will deconstruct how the data directory preserves the server's state, but first, let's look at what a typical RabbitMQ node data directory would look like. The node in question has one classic queue, one quorum queue, and one stream queue.

Figure 1 - RabbitMQ data directory
In the image above, you’d see that there is one top-level
mnesia
folder – where this top-level folder also has two sub-directories
(default@localhost, default@localhost-plugins-expand)
and two files
(default@localhost-feature-flags, default@localhost.pid).
-
default@localhost –This is the name of the node running on the server. If you are working with mutliple RabbitMQ nodes running on the same server, there would be a folder for each node in/mnesia. -
default@localhost-plugins-expand —This folder contains the uncompressed code of all the third-party plugins installed on the default@localhost node. It’d be empty if you have none enabled. -
default@localhost-feature-flags –This file contains information about all the feature flags enabled on thedefault@localhostnode -
default@localhost.pid –Contains the process ID of the node
Moving into the node directory,
default@localhost,
the
msg_stores
folder
houses all the classic queues related data,
quorum and stream
folders contain the quorum and stream queues-related data respectively.
Most of the rest of the files are Mnesia files. Mnesia?
We will see what Mnesia is, later on, but first, let’s look at how the data directory preserves the server state.
Data directory and server state preservation
The data directory preserves the state of the server in two ways:
- By persisting messages published to queues on disk using custom built solutions different for each queue type
- By persisting other meta-data on disk, via Mnesia
On message persistence
In the image shared previously, there are, in the main, four directories that are
responsible for message persistence:
msg_stores, quorum, stream, and coordination.
In your case, your node might only have just some or all
of these folders depending on the type of queues you’ve created on your
node.
-
msg_stores –this directory persists messages published to all the classic queues on the node, together with some meta-data. For example, sequence id within a queue or acknowledgement status. -
quorum –this directory persists all the messages published to all the quorum queues on the node. -
stream –this directory persists all the messages published to all the stream queues on the node. -
coordination –this directory persists all the data related to Raft – the consensus algorithm responsible for leader election and consistent storage. Two Raft systems use this directory. One does leader election and membership bookkeeping for stream queues. The other stores MQTT client ids. This latter system won’t be used by the new Native MQTT implementation in 3.12 if the feature flag “delete_ra_cluster_mqtt_node” is enabled.
To give you a sense of how messages are persisted under the hood,
let’s explore the
msg_stores, quorum, and stream
directories.
But before we proceed, let's take a brief detour to explore journal files. If you want, you can skip this part, as it's not essential for understanding the layout of the data directory. Nevertheless, you might find these details interesting.
The journal files
The concept of a journal file or write-ahead-log is used in multiple storage implementations within RabbitMQ. The main idea is to record all actions or changes in an append-only file as they occur, preserving their order. While this file format is efficient for writing, it's not ideal for reading, searching, or processing.
The system periodically(usually when the journal reaches a certain length or size) dumps the content of the storage into a different format. Usually, this dump might involve segmentation or indexing, processing or compression, making it easier to handle later. After the dump, the journal is emptied.
The journal serves a crucial purpose: in case the system crashes between two dumps, the list of actions can be "replayed" from this file. This allows the system to restore the last content of the storage accurately.
With that being said, let’s cycle back to exploring the layout
of the
msg_stores, quorum, and stream
directories.
/msg_stores
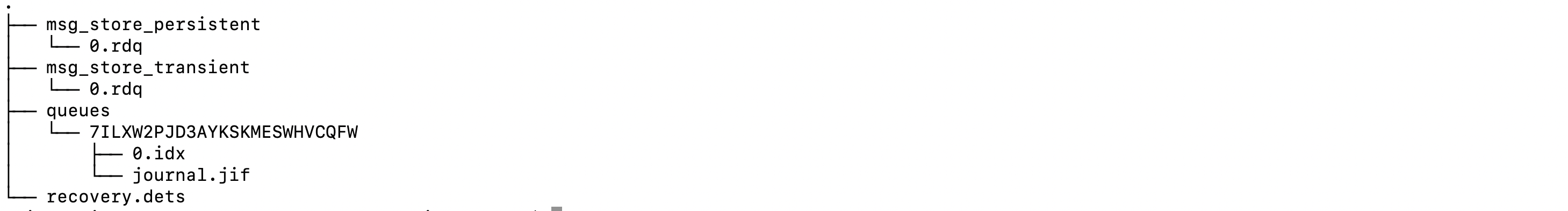
Figure 1 - Message store file tree
The image above shows the content of the
msg_stores
directory.
Classic queues persist each message they receive using two separate but
related directories: queues and
(msg_store_persistent or msg_store_transient)
If intentionally simplified, we can infer that the
queue
folder keeps
track of message indexes, while the actual messages are stored in
msg_store_persistent or msg_store_transient directories,
depending on whether the message is persistent or transient.
In essence, the
queues
directory is where the message index is
persisted, with one sub-folder for each queue. You can find the
queue name the folder belongs to in the
.queue_name
file. Classic queue v1 also uses a journal file that we
mentioned above. On the other hand there are no sub-folders in
msg_store_persistent or msg_store_transient.
Messages from all queues in one vhost are stored here.
While how we described message persistence in classic queues in the paragraphs above is mostly right, for want of a simplified way of explaining this concept, we abstracted a lot of details. However, you can read our blog post on message store and queue index that explains how this works in classic queues v1 in more detail.
But if you are also interested in understanding how this works in classic queues v2, you can also check out this RabbitMQ documentation of both classic queues v1 and v2.
Finally, you might have spotted the
recovery.dets
file. It holds
non-essential information about the state of the message store.
It makes startup faster by not having to scan all files, but if
it is not available the information can be gathered from other
files as well.
If a queue grows too large so that it prevents RabbitMQ from
starting up (the content of a sub-folder is huge), you can delete
all files in that queue’s sub-folder (but keep the folder itself) and
the
recovery.dets
file. This will lose all messages in only the
problematic queue but at least RabbitMQ can start up and other
queues are left intact.
On the other hand if you delete the whole mnesia folder, RabbitMQ will start from scratch and not just all the messages from all the queues are gone but also meta-data like queue and exchange definitions, users and permissions, policies and others.
/quorum

Figure 1 - Quorum queue file tree
The image above shows the content of the
quorum
directory.
Just focusing on the important details here, first of all, note that the internal quorum implementation creates one sub-directory in the quorum folder for each quorum queue declared on the respective RabbitMQ node.
In our case, we’ve created just one quorum queue and as a result one
sub-directory,
2F_TESI49NYCVV6XT5,
has been created for that queue. If there were more than one quorum
queues on the node in question, then there would have been more sub
directories.
Generally, the sub-directory created for a quorum queue would have some
segment files and a snapshot directory as is the case with the
2F_TESI49NYCVV6XT5
sub-directory. All together, these files persists the actual messages published to
the quorum queue in question as well as a snapshot of the queue at a
point in time.
However, messages published to all the quorum queues on a node are first
written to a shared Write Ahead Log file(.wal) – in this case the
00000002.wal
file. Eventually, these messages are
flushed to their respective segment files.
The flushing process occurs when the current write-ahead log (WAL) file reaches a predetermined threshold. Worth noting that all the entries in the WAL file are also stored in memory. At flushing, not only the WAL file is emptied, but also the occupied memory is released.
While the default size limit for flushing the WAL file to disk is 512 MiB, it can be adjusted as per your configuration needs (eg. in case of a server with smaller memory) the following way:
raft.wal_max_size_bytes = 64000000
The snippet above will flush current WAL file to a segment file on disk once it reaches 64 MiB in size.
/stream

Figure 1 - Stream queue file tree
The image above shows the content of the
stream
directory.
This directory generally has a relatively simpler file structure than the classic and quorum queues. The stream implementation also creates one sub-directory for each stream queue declared on the node in question.
In our case, since we only created one stream queue, there is just one
sub-directory,
__test-stream-queue_1682622270451972028.
The sub-directory name contains the queue name in a readable format,
so they are easy to identify.
Each stream queue has an index and a segment file in its sub-directory as is the case in the image above.
On meta-data persistence
In addition to messages, the data directory also persists some meta-data about the node. Aside from the message persistence directories, all the other files in the Mnesia directory hold some meta-data.
The files with extensions DCD or DCL are handled by the Mnesia
database while there are some other files
(either internal files of Mnesia which we can ignore or mostly
human readable files created by RabbitMQ directly
like node_running_at_shutdown).
Each file is named in a manner that gives an idea of what meta-data it holds.
For example, the
rabbit_durable_queue.DCD
file keeps a record of all the durable queues declared on the node in question while
rabbit_durable_exchange.DCD
keeps a record of all the durable exchanges created – again, these files
map to certain Mnesia tables.
You might have noticed that .DCD files come with accompanying .DCL files.
The DCD files keep a record of the actual data as it is in memory. For
example, the
rabbit_durable_queue.DCD
file would keep a record of the names of all the durable queues created on that node.
The DCL files, on the other hand, are write-ahead-logs. As you can see, Mnesia also uses this concept that we discussed before.
We’ve thrown the word Mnesia around here a lot. Now, let’s answer the one question lingering on your mind.
What is Mnesia?
Simply think of Mnesia as the database that holds the entries of some of the files in the data directory – more specifically, queues definitions, bindings, exchange definitions, and other metadata. It ensures that the data survives server restarts, crashes, or other failures.
Essentially, each definition file mentioned above is mapped to a table in the Mnesia database, with every entry in the file representing a row in the DB.
Unlike most DBMS, the Mnesia database is included in the Erlang release – think of it as one of Erlang’s standard libraries – it runs within the Erlang Virtual Machine and persists data as native Erlang constructs.
Because RabbitMQ was written in Erlang, the developers figured out they could just use Erlang’s built-in distributed database, Mnesia, to implement RabbitMQ’s persistence layer. Over the years, they realized they can do better so worth noting that a custom-built, Raft-based storage called Khepri. Khepri will replace Mnesia as the persistence layer in RabbitMQ 4.0.
Thus, when we talk about Mnesia files, we are simply referring to the meta-data files whose actual content is persisted in the Mnesia database.
Conclusion
RabbitMQ files and directories play an essential role in the proper functioning of the message broker. By understanding the distinct functions of each file and directory, you can effectively manage the RabbitMQ broker and customize its behavior to meet your specific requirements, and, equally important, you’ll know how your actions would impact the server.
The configuration files allow you to modify the broker's settings, while the log files help to monitor the broker's health. The data directory stores the broker's persistent data and, by extension, preserves the server’s state.
New to RabbitMQ? Read our RabbitMQ Beginner Guide
Easily create a free RabbitMQ or free LavinMQ instance today to start testing out message queues. You will be asked to sign up first if you do not have an account, but it’s super easy to do. For any suggestions, questions, or feedback, get in touch with us at contact@cloudamqp.com
