RabbitMQ 3.13.0 was released earlier by the RabbitMQ core team and we are happy to announce that RabbitMQ 3.13.2 is now available on CloudAMQP. This blog will review the three key user-facing changes coming in this release:
- The introduction of Khepri, the new metadata store
- Stream filtering
- MQTT 5 support
Khepri: The new metadata store
Since its inception, RabbitMQ has utilised the Mnesia DB to persist metadata like exchange and queue definitions, bindings, users, vhosts etc. However, this will soon change– Khepri will replace Mnesia in RabbitMQ 4.0 and is currently available in RabbitMQ 3.13 for testing. But why replace Mnesia, you ask?
In RabbitMQ netsplit scenarios, client applications could keep writing to the Mnesia table of the individual RabbitMQ nodes. Consequently, the tables diverge, leading to inconsistent data across the different nodes. This begs the question, how does Mnesia resolve this data inconsistency after the netsplit has been resolved?
The default behaviour of Mnesia is not to attempt an automatic conflict resolution after a 'partitioned network' event. It detects and reports the condition, but leaves it up to the user to resolve the problem. RabbitMQ offers some remedies, but they are not very robust.
Khepri, while independently usable in any project built with Erlang or Elixir, is notably designed to address challenges around recovery from network partitions with Mnesia. Khepri makes recovery from network partitions in RabbitMQ a lot more predictable.
You can read our blog, Khepri Overview and Motivation to learn more about what Khepri is about and how it simplifies the issues around recovery from a network partition with Mnesia.
Working with Khepri in RabbitMQ 3.13
Note that Khepri is only available in RabbitMQ 3.13 as an opt-in feature only. As a result, upgrading to RabbitMQ 3.13.2 will not automatically make Khepri available. You’d have to enable Khepri first.
But before you enable Khepri in your cluster, we strongly recommend that you read our blog, How Khepri Affects you to learn more about what to expect when you switch to Khepri.
Stream Filtering
Imagine a scenario: A stream queue with messages(payment data) from all over the world and three consumers, with each consumer interested in just a sub-set of the messages— one country per consumer:
- First consumer: United States
- Second consumer: Sweden
- Third consumer: New Zealand
Prior to RabbitMQ 3.13.0, the only way to implement a scenario like that was to send all the messages in the queue to each consumer. Each consumer then filters the messages it receives.
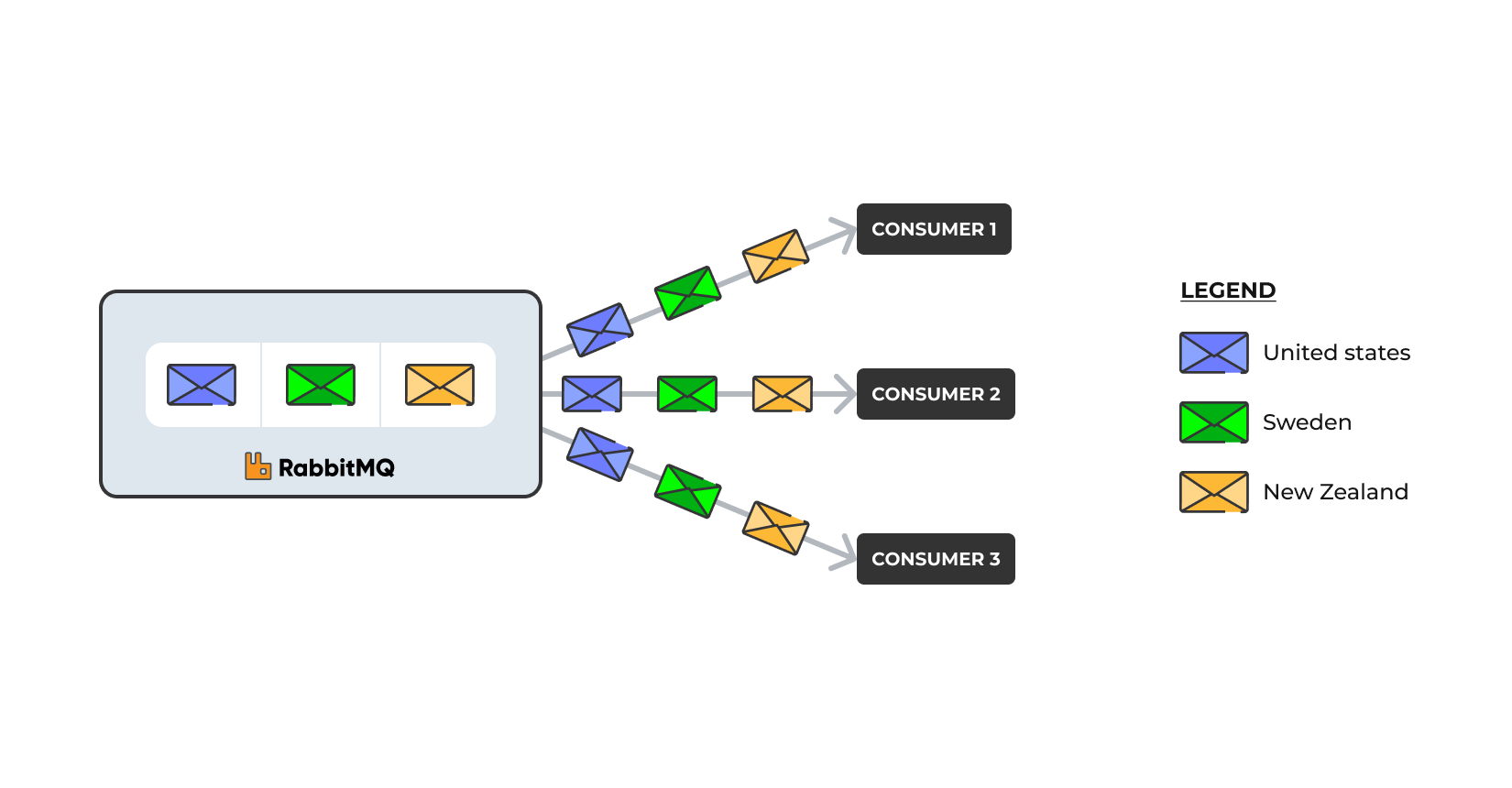
The above approach works, but the entire queue content is sent over the network, repeatedly. In our case, the queue only has 3 messages, so just 9 messages in total sent over the network. In reality, a stream queue is immutable and could grow to thousands or even millions of messages.
To avoid sending redundant data over the network, stream filtering was introduced in RabbitMQ 3.13.0.
Stream filtering provides an initial filtering step on the broker side before delivering messages to consumers. As a result, consumers only receive the subset of messages they're interested in, instead of receiving all data and filtering it themselves. Less data is transmitted to consumers, leading to less bandwidth usage — This is the primary reason why stream filtering was introduced.
But how does it work?
Stream filtering works based on a filter value: A publisher publishes a message with a filter value, in our case, the country code where the payment data originates from. This filter value is then associated with the message in the queue:
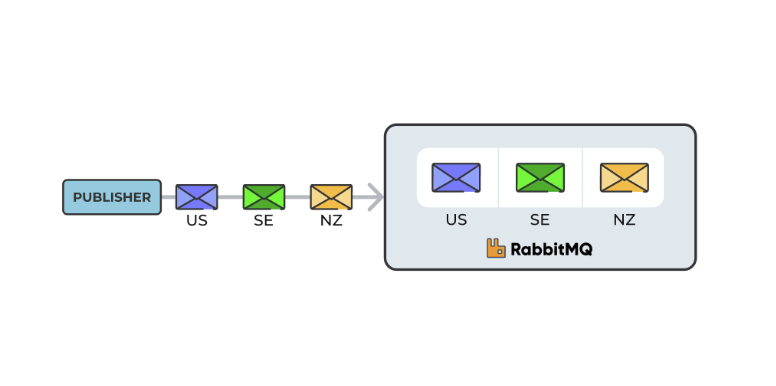
On the consuming side, when a consumer subscribes, it can specify one or more filter values and the broker only sends the messages with this or these filter value(s) to the consumer.
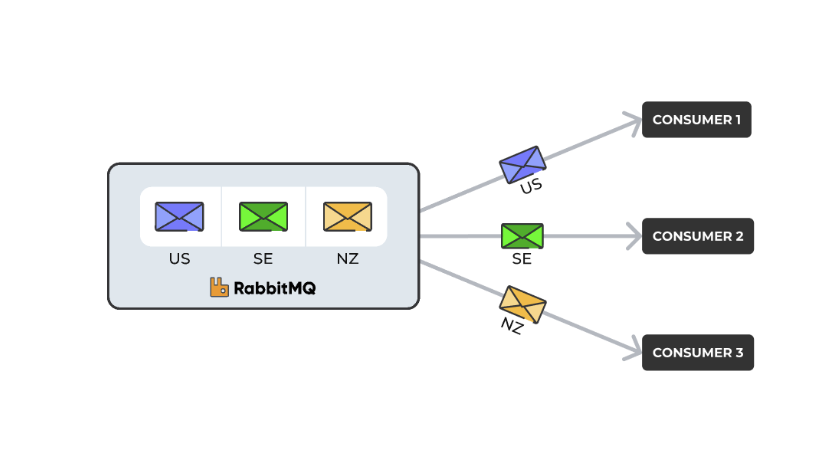
Revisiting our previous scenario, the consumer at the top specified
it only wants
US
messages and the broker sends only those, instead of sending all
the messages in the queue to the consumer. Same thing for the other
two consumers interested in
SE
and
NZ
messages, respectively.
Earlier we stated that when a consumer subscribes to a queue, it can specify one or more filter values and the broker only sends the messages with this or these filter value(s) to the consumer. That statement is not very accurate in practice.
The stream filtering implementation uses the bloom filter approach, which is probabilistic — A consumer could end up with some messages it’s not interested in. Usually, a consumer would also implement its own filtering logic. There is a great blog on stream filtering — you can check it out to learn more.
Working with stream filtering in RabbitMQ 3.13
Upgrading to RabbitMQ ≥ 3.13.0 (starts from 3.13.2 on CloudAMQP) will automatically integrate the stream filtering feature, no special action is needed. The last section in this blog covers how to upgrade to 3.13 on CloudAMQP.
Furthermore, stream filtering is only possible via the stream protocol, or using stream clients (and needs the stream plugin to be enabled). It is not supported when consuming from a stream queue via the AMQP protocol.
MQTT 5 support
Recall that native MQTT was introduced in RabbitMQ 3.12, leading to substantial performance improvements in RabbitMQ’s support for the MQTT protocol. In this release, the work on MQTT has been consolidated even further. The MQTT and Web MQTT plugins that previously only supported MQTT 3.1.1, now support MQTT 5 as well.
MQTT 5 comes with a set of new features that have been incorporated into RabbitMQ in the 3.13.0 release. The MQTT 5.0 Support in RabbitMQ 3.13 blog goes into the details of how the new MQTT 5 features are used in RabbitMQ — You can check it out.
Working with MQTT5 in RabbitMQ 3.13
Upgrading to RabbitMQ ≥ 3.13.0 (starts from 3.13.2 on CloudAMQP) will automatically integrate MQTT 5, no special action is needed. The last section in this blog covers how to upgrade to 3.13 on CloudAMQP.
Other notable features coming in 3.13
- Significant performance and stability improvements had been made to classic queues in RabbitMQ 3.13.
- Message containers — which makes interoperability between different protocols smoother and more correct.
Erlang 26 and TLS
Under the hood Erlang also gets a major version bump. Every major Erlang version can have TLS changes, so it is advisable to test interoperability with your clients on a test cluster to ensure secure connections still work. Changes worth noting:
- Now, peer verification is enabled by default, when your cluster as a TLS/AMQP client connects to other clusters or services. This primarily affects shovels and federation, but can also impact HTTP or LDAP auth servers.
- Some elliptic curve cipher suites are disabled by default even on TLS 1.2.
Note to CloudAMQP customers
If you host your RabbitMQ cluster with us at CloudAMQP, here are some things to keep in mind.
Khepri and plan changes
Enabling Khepri via the Management interface is currently blocked. Contact support to learn about caveats and to have it enabled for testing.
The reason is that our current plan change mechanism relies on mirroring for classic queues and HA-policies, but they are not supported by Khepri. During certain types of plan changes on CloudAMQP, instance type change or disk shrinking is achieved by adding new nodes to the RabbitMQ cluster and removing old ones. To preserve queue data during this process, replication is crucial, which in case of classic queues means mirroring.
Reworking the plan change procedure is ongoing, so the content of the data directory is preserved when a node is replaced, and there will be no need for queue replication to preserve queued messages.
Until then when you request to have Khepri enabled, HA-policies need to be removed manually and during a plan change messages in classic queues will be lost.
Deprecated features
RabbitMQ 3.13 introduced the notion of deprecated features. When you open the Management UI you will see a warning banner “Deprecated features are being used. [Learn more]”.
This is normal as every cluster on CloudAMQP has default HA-policies defined. There is a dedicated page of the Management UI under the Admin page which lists the deprecated features and provides more information about them.
How to upgrade to RabbitMQ 3.13 on CloudAMQP
Upgrading to RabbitMQ 3.13.2 is a simple process if you already have a CloudAMQP cluster. You can upgrade from the Nodes view in the CloudAMQP Console or via the API.
It is also advisable to keep your Erlang version up to date while upgrading your RabbitMQ version. However, note that for upgrades to RabbitMQ versions > 3.9, the Erlang upgrade will be handled automatically on CloudAMQP. So, you don't need to worry about that.
You can read our blog post on Erlang and RabbitMQ upgrades for more information.
