Business continuity in the context of messaging is about making sure your broker can keep running, even when trivial or significant incidents arise. To achieve business continuity, there are two key approaches:
- High Availability (HA): Involves having automated fail-over systems that kick in when something goes wrong, like a server or disk failing, or a local network issue. The goal is to keep any downtime very minimal or even invisible to users.
- Disaster Recovery (DR): Deals with much bigger disruptions, such as the complete loss of a data center or severe data corruption. It focuses on recovering from these major incidents by having a backup system in a different location to avoid permanent loss of service or data.
This blog will focus on disaster recovery and, more precisely, the different strategies for recovering from a disaster on CloudAMQP. However, it is important that we first look at two key metrics to keep in mind when deciding what recovery strategy to adopt: RTO and RPO.
Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
In disaster recovery planning, RTO and RPO are critical metrics that help organizations define their tolerance for downtime and data loss, respectively:
Recovery Time Objective (RTO)
This is the maximum acceptable time a system can be down after a failure or disaster occurs. It represents how quickly you must restore your service to maintain business continuity. For example, an RTO of 4 hours means your system should be operational within 4 hours of an outage.

Recovery Point Objective (RPO)
This refers to the maximum amount of data loss an organization can tolerate during a disaster. It's measured in time and indicates how recent your backup data should be. For instance, an RPO of 1 hour means you can afford to lose up to 1 hour's worth of data in the event of a disaster.

Depending on your RTO and RPO requirements, you can configure your DR cluster as either a hot standby or a cold standby on CloudAMQP. The choice between these approaches depends on your specific business needs, the criticality of your messaging system, and your budget constraints. Let’s look at each technique, one at a time. But first, a quick note on how CloudAMQP handles definitions back-up.
Note on definition backups
CloudAMQP takes definition backups every 8 hour. If you wish to have more frequent backups, you can easily configure an application to call the HTTP api endpoint /api/definitions mored frequent, and back up the definitions in a data store you prefer. API docs: LavinMQ / RabbitMQ
You are also able to easily upload your own definitions when creating a new cluster in CloudAMQP. Note that no backups of message data is taken from CloudAMQP.
Cold Standby
In this approach, a secondary broker is set up but remains inactive until a failure occurs. The secondary cluster is only brought online when the primary cluster fails. A cold standby approach generally has higher RTO and RPO, as it takes more time to set up the backup system and may not have the most recent data.
For CloudAMQP, using cold standby means creating a new cluster when an incident occurs, based on your current definitions. Cold standby has a longer RPO because some messages in the original cluster might not have been consumed at the time of the disaster. It also has a longer RTO due to the time needed to set up a new cluster and switch clients. However, it’s more cost-effective since you don’t need to run a secondary cluster all the time.
Creating a cluster based on definitions will ensure that the new cluster mirrors the old. CloudAMQP backs up definitions every 8h. As with any backup, we encourage you to test the backups regularly to ensure no surprises.
Note: The connection strings will differ because the hostnames of the two clusters are not the same. If you can't easily change the connection string your clients use, consider using our custom hostname feature. This way, if you switch to a new cluster, the hostname still stays the same.
Hot Standby
Hot standby in disaster recovery means having a fully operational backup system that mirrors the primary one in real-time. This backup is always up-to-date and ready to take over instantly if the main system fails, minimizing downtime and data loss. It ensures you have the latest data available (minimizing RPO) and allows for a quick switchover (short RTO), based on how fast you can redirect clients to the backup.
In CloudAMQP, you can achieve this using exchange federations. However, note the following about setting up a hot standby using exchange federation:
- It can be done on a per-exchange level, meaning you are not required to copy every exchange, but can select the ones most crucial for your business.
-
It can not be done on the default
amq.directexchange, or any exchange with theinternalflag set totrue.You will need to declare custom exchanges.
With that in mind, take the following steps to set up your hot standby DR cluster on CloudAMQP.
Step 1: Create a DR cluster
Start by creating a disaster recovery cluster. It’s recommended
that you create it based on the definitions on your production cluster.
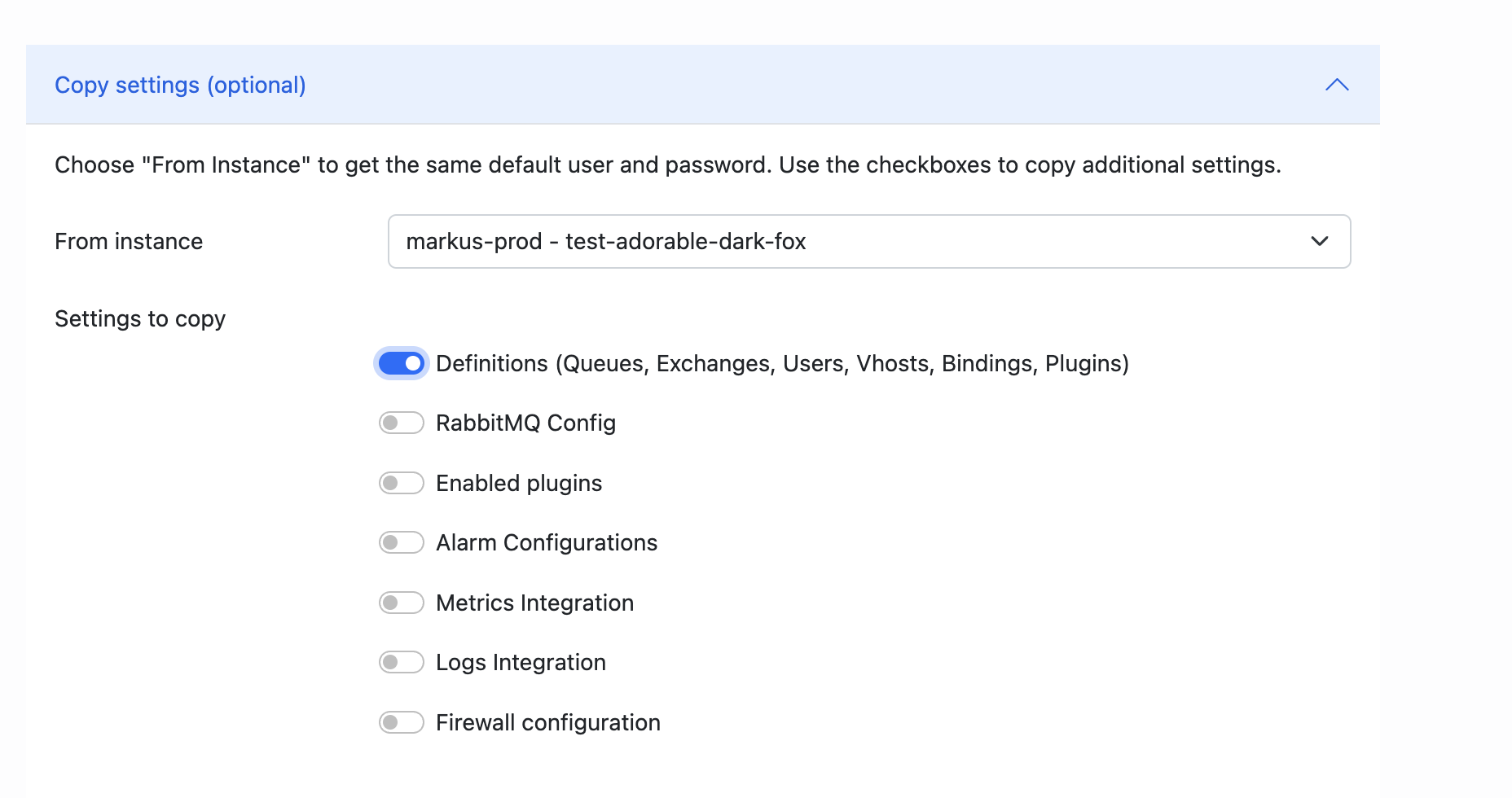
To do so, simply expand
Copy settings ,
Set
From instance
to your production cluster, and enable
Definitions
under
Settings to copy.
Side notes on creating your DR cluster
- We recommend creating your DR cluster in a different region from your production cluster.
- Since the DR cluster is temporary, the cost of a multi-node setup might not be justified. CloudAMQP allows easy horizontal scaling within the same plan, so start with a 1-node cluster and increase disk space as needed.
- If multi-node is needed, use quorum queues instead of classic mirrored queues, which can be resource-heavy and deprecated in later versions.
- To keep the schema in sync, regularly export definitions from your production cluster and import them into your DR cluster. This ensures all queues, exchanges, users, and bindings are replicated.
- You can mix backends as long as you do not use backend-specific features. For example, you can copy definitions from a RabbitMQ CloudAMQP cluster to a LavinMQ cluster.
Step 2: Create federation upstream
When your DR cluster has finished bootstrapping, it’s time to configure
a federation upstream. This is done under
admin → federation upstreams.
Once created, it should look something
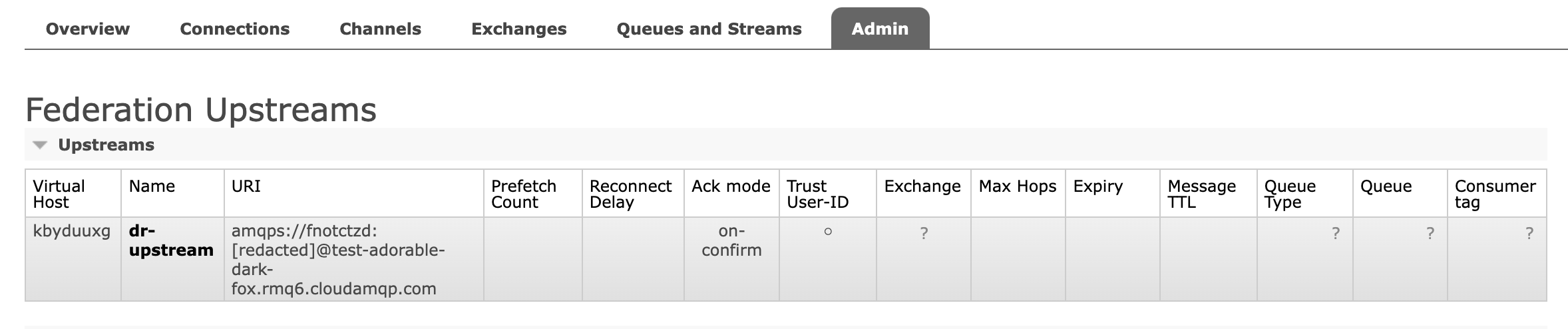
Step 3: Create a policy
Next, create a policy that will apply to exchanges you wish to federate.
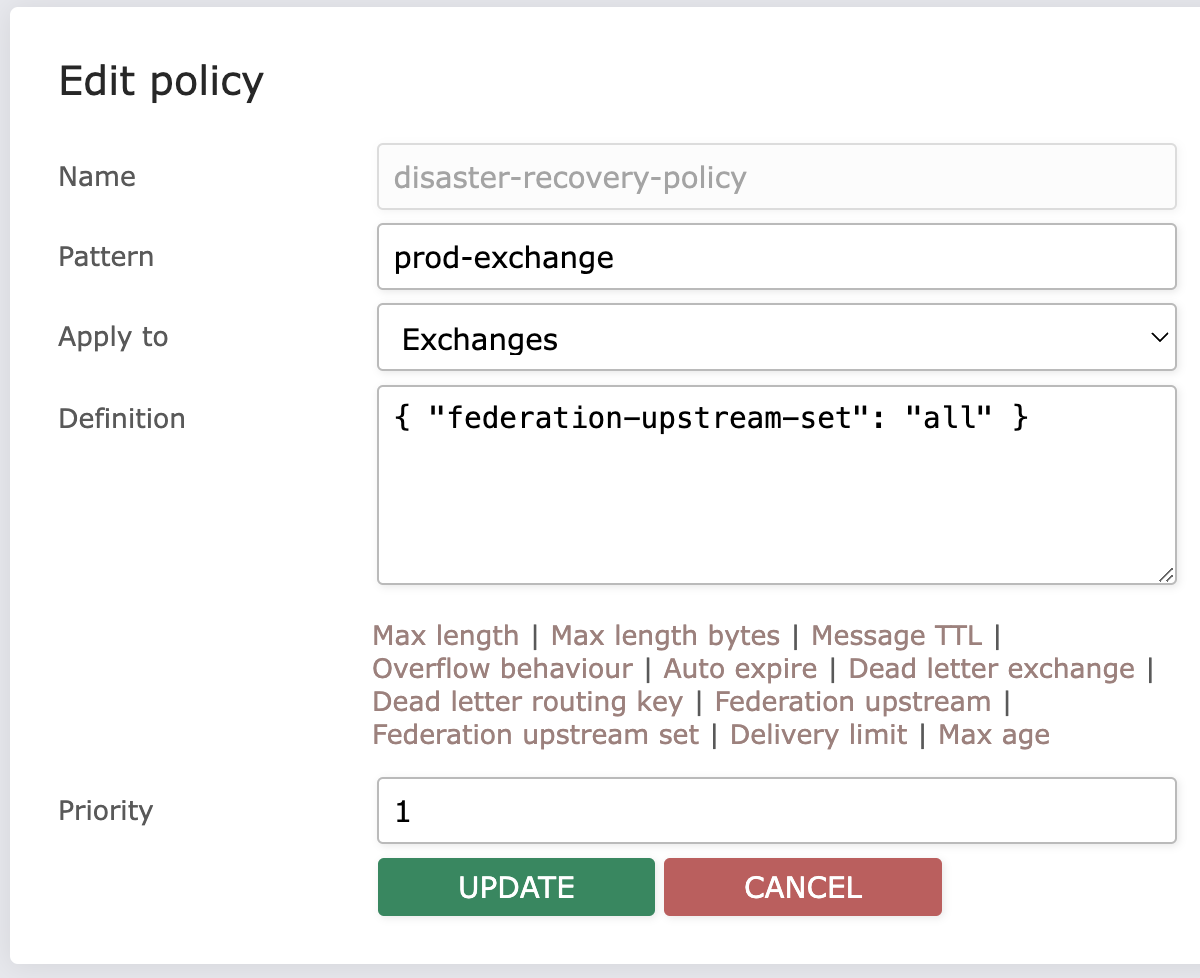
Once upstream status is verified to be good, the federated exchange link should be visible in your production cluster. You should also see messages starting to copy over to your DR cluster.
Caveats
Once confirmed working, here are some factors to consider:
Queue length and message TTL
Set a queue-length policy and message TTL on the DR cluster to control message lifespan and queue size, determining when messages are discarded or dropped, respectively, based on your overflow settings. LavinMQ RabbitMQ.
The queue-length and message TTL are important to consider to avoid message loss. For example, if your message TTL is 3h, but on your production cluster you have long queues that are being processed slowly and oldest message is 4h, it will already be gone on the DR cluster if the production cluster goes offline. However, if your policies allow messages to remain longer and queues to grow longer, you run the risk of running out of system and disk resources.
Idempotency
Another important factor to consider is idempotency. If you move your consumers to the DR cluster, it is likely that some will re-process messages that have already been processed on the production cluster. So, your consumers need to be able to handle this.
We recommend you test migrating to the disaster recovery cluster regularly to ensure current sizing keeps up with load, and that your clients can manage the workload on the DR cluster.
Synchronized definitions
Also, in order to keep your DR cluster up to date, you should make sure new queues/bindings/exchanges are synchonized between your production and your DR cluster. One way of doing so is to export/import definitions regularly. This can be done either using the HTTP API or the CloudAMQP console GUI.
Conclusion
Disaster recovery is key to keeping your messaging infrastructure operational in the face of disruptions. For disaster recovery strategies, CloudAMQP offers two techniques: cold and hot standby setups, each suited to different RTO and RPO requirements — whether you’re aiming for a minimal data loss or minimal downtime.
Need help setting up your disaster recovery cluster on CloudAMQP? Feel free to get in touch with our support team - we’d be happy to help. Thank you for reading!
